Watch all of Fathom’s EGU research presentations here.
As part of #EGU22, Dr Laurence Hawker presents his research into the development of the first freely available global DEM to remove both forest and building artefacts.
Video transcript:
Hello everyone and thank you for joining today. My name is Laurence Hawker and I’m from the University of Bristol. Today I’ll be briefly talking about FABDEM a 30-meter global map of elevations with forests and buildings removed.
This presentation is being given as part of the EGU conference where the format is very short so I’ll be going over this topic quite superficially. If you want to know more details please do contact us or read the open-access paper available for free online.
So, what is FABDEM?
FABDEM is the first freely available global DEM to remove both forest and building artefacts. It corrects the Copernicus GLO 30 DEM and has complete global coverage – unlike DEMs such as SRTM.
The data uses a wide range of reference data for machine learning training. This image is an example of this. On the right-hand panel so FABDEM is shown. Other panels display comparative global DEMS.
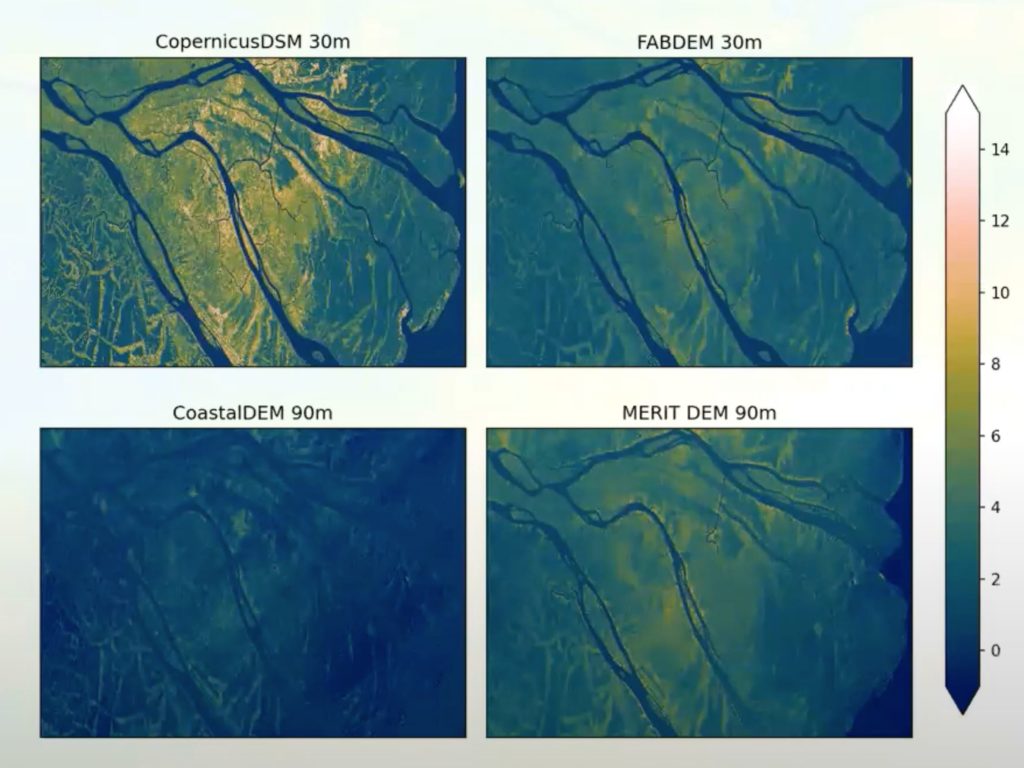
We’ve corrected data from the Copernicus DEM which is in the top left and we can see quite a substantial correction. We’ve been able to create a nice looking map which has a broad range of applications that require a digital terrain model that provides an accurate simulation of the terrain.
Typically, LiDAR-based DEMs are the gold standard. However, high quality LiDAR is only available for a very small fraction (est. 1%) of the world’s land surface.
This is why we need a global digital terrain model (DTM) to fill these gaps. Until FABDEM, Merit DEM was probably the closest to a DEM which corrected SRTM and removed forests. However, a major problem was that no buildings were removed.
How did we produce FABDEM?
We utilised a three-stage workflow, as depicted in the image below:

The first thing needed were data predictors so that we could predict the height of the forest and the buildings. Our team used a vast range of reference elevation data in order to characterise as many types of buildings and trees as possible. In order to do this, we sourced LiDAR from 12 different countries covering a wide range of urban landscapes and climatic zones.
Step two was where we began conducting the actual corrections. We divided it into forest buildings and corrected the surface as provided in the Copernicus DEM.
We post-processed this data in the third stage. So here, we merged both the first building correction to the minimum height and then we applied various image filters. We needed to do this because buildings and forests were sometimes over or under corrected in step two. Therefore, this image processing filter corrected errors in our predictions.
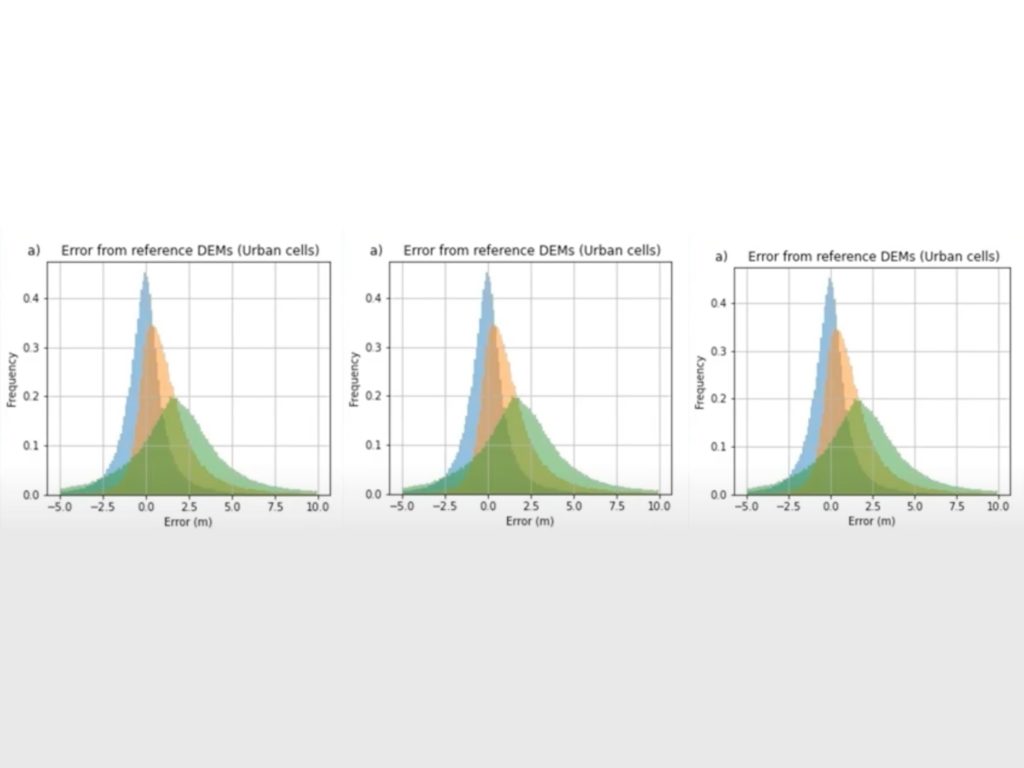
These density distribution plots showcase what the error stats looked like. The blue is FABDEM, the orange is Copernicus (I.e. what we were correcting), and the green is Merit DEM.
In FABDEM, we can see that the converges a lot closer to zero and we can kind of see these in the error stats. When comparing Copernicus down to FABDEM we see quite a reduction in the medium and absolute error, and to visualise this on a map we also compared.
Here’s an example of maps from St Louis, USA (See 4:35). This shows how FABDEM’s elevation data compares against LiDAR and MERIT. Again, we use LiDAR as the gold standard, however, in many parts of the world it has low availability. We can see that fab damn looks a lot more similar to LiSAAR and that’s what we want to see.
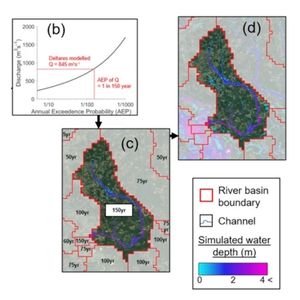
To understand what it looks like in application, we ran a hydrodynamic flood model and this example is from Australia (See 5:14). In a similar theme to the previous slide, we find that FABDEM does a pretty good job in comparison. Where LiDAR is available you should use that but where it is not, FABDEM is an excellent alternative.
There is a more detailed explanation of this in the paper which you can access here.
Thank you very much for your time today. If you have any additional questions please get in contact and I’ll be happy to answer those.