-
Kratzert, F.,
-
Nearing, G.,
-

-
Erickson, T.,
-
Gauch, M.,
-
Gilon, O.,
-
Gudmundsson, L.,
-
Hassidim, A.,
-
Klotz, D.,
-
Nevo, S.,
-
Shalev, G.,
-
Matias, Y.

Caravan gives users the opportunity to collectively accelerate the understanding of water risks and resources at the global level.
Caravan is a hydrological dataset that draws on the strengths of regional large-sample hydrology (LSH) datasets, such as the CAMELS datasets, while also overcoming their constraints.
It was created to provide the hydrological community with accessible, crowd-sourced data that support studies into global flood risk, drought risk and water availability.
A new academic paper describes how Fathom’s principal hydrologist, Dr Nans Addor, co-developed Caravan with experts from Google, Johannes Kepler University (Austria) and ETH Zurich (Switzerland).
Published in the peer-reviewed journal Scientific Data, the paper outlines the team’s vision for Caravan to expand, evolve and provide “the most direct path” to a truly open global hydrological dataset.
Dr Nans Addor is Fathom’s Principal Hydrologist
Learn how Nans’ expertise underpins Fathom’s products
CAMELS research from Fathom
Discover previous CAMELS (Catchment Attributes and MEteorology for Large-sample Studies) datasets that were leveraged to create Caravan in these free-to-read research papers.
Why create the Caravan?
Several large-sample hydrology (LSH) datasets have been released in the last few years and widely adopted by academic and industry scientists. Although these datasets are high quality, they still carry constraints.
LSH datasets provide an easy-to-use combination of valuable hydroclimatic time series (atmospheric and river flow data) and socio-biogeophysical attributes, including topography, land cover, soil, geology and level of human interventions.
With data from hundreds to thousands of catchments, regional LSH datasets’ have enabled major advances in hydrological modeling and science. Hydrologists use LSH datasets to:
- Systematically explore hydrological processes across hydroclimatic regions
- Benchmark and improve hydrological models
- Accelerate the use of machine learning in hydrology.
Large-sample hydrology dataset limitations
Yet, there are a number of limitations to LSH datasets. Firstly, there is no comprehensive, global LSH dataset, making them unsuited to global studies. Previous research led by Dr Nans Addor outlines further limitations of LSH datasets:
- Lack of common standards: prevents intercomparison and global analyses.
- Lack of uncertainty estimates: compromises assessments of data reliability.
- Lack of information about human interventions, such as reservoir storage: prevents accurate assessments.
- Inaccessibility (e.g., they are undigitized or subject to a fee): acts as a roadblock to research.
Addor and research partners developed Caravan to tackle these obstacles.
The basis of Caravan hydrological dataset
The Caravan dataset is built with cloud-based infrastructure that enables anyone in the hydrological community – whether student, practitioner or engineer – to benefit from its data and extract data for additional catchments.
In the paper, the research team describes their vision for Caravan to act as a platform for a larger community data resource. They invite members of the hydrological community to contribute new data to Caravan stating: “We see this as perhaps the most direct path to developing a truly open global hydrological dataset.”
To support this vision, the dataset meets three key criteria:
- 1. Standardized: Data are standardized globally. All catchments have the same meteorological and landscape variables, which are derived from the source datasets using the same procedures.
- 2. Open: All data are publicly available with an open license.
- 3. Extensible: All software tools and source datasets are open and accessible through a cloud platform (Google Earth Engine). This enables others to extend the dataset (i.e., add catchments).
The extensible nature of Caravan is especially important. Streamflow gauges are usually maintained by local or national organizations, and their data are rarely FAIR (Findable, Accessible, Interoperable and Re-usable).
Which catchments are currently in Caravan?
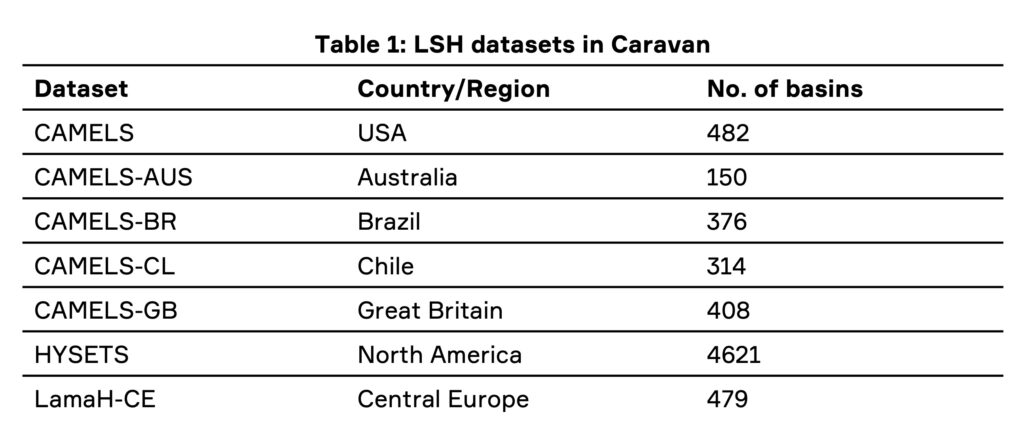
The core version of Caravan (described in Kratzert et al. 2023) merges and standardizes seven LSH datasets for specific countries or regions datasets.
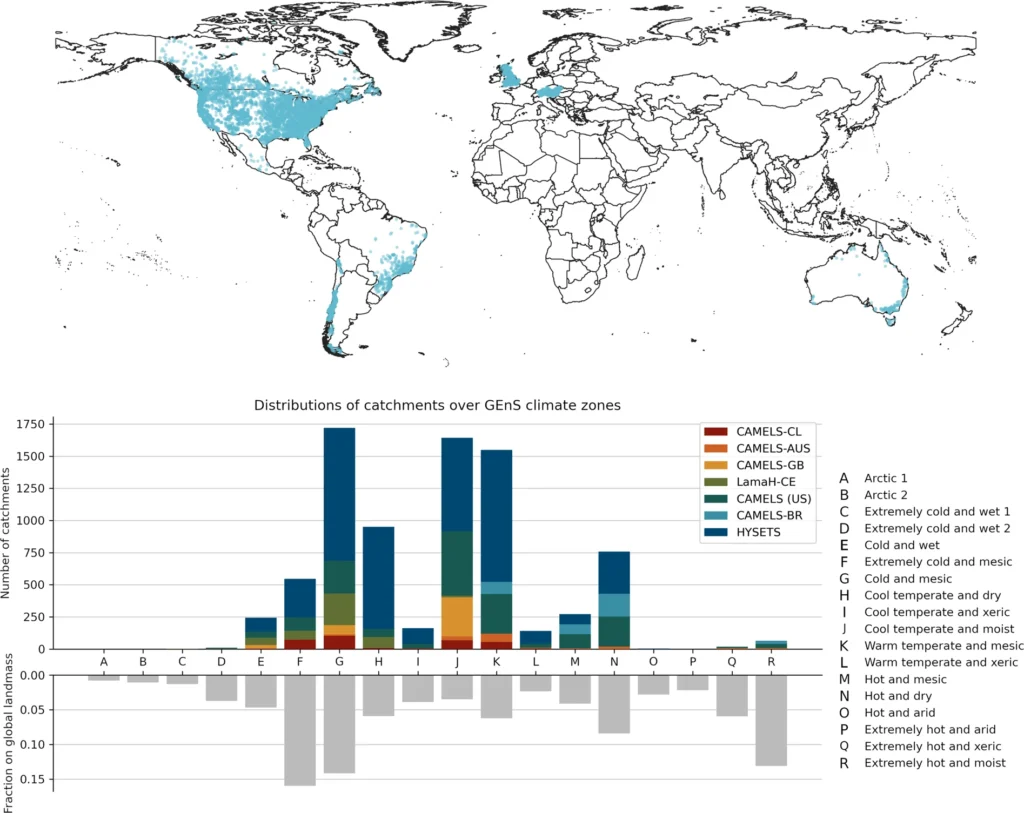
These datasets span 6830 basins in North America, South America, Australia and Europe (see Table 1 and Figure 1) and, therefore, most Global Environmental Stratification climate zones. They further contain daily data from almost four decades (1981–2020), including from catchments that have experienced significant climate trends.
The research team selected these seven LSH datasets because:
- they include catchment boundaries for each streamflow gauge
- their licenses allow redistribution of the daily flow of data
Which data are in Caravan?
Caravan includes:
- Daily flow time series. These data come from the regional LSH datasets (Table 1).
- Meteorological forcing data from ERA5-Land. These data are global, consistent, have a sub-daily (e.g. hourly) resolution which enables us to account for the local time zone when computing daily means, are available in the cloud and have a permissive license.
- Modeled soil moisture and snow states, also from ERA5-Land. These time series provide reference values for studies that analyze or model hydrological states.
- Catchment attributes derived from HydroATLAS and ERA5-Land. These can be loosely grouped into the following categories: hydrology, physiography, climatology, soils and geology, land cover characteristics, and anthropogenic influences.
Are more catchments being added to Caravan?
Extensibility is a key feature of Caravan. Since the release of the care Caravan dataset, several extensions have been produced (following Caravan’s extensions process) and made publicly available. These include:
- GRDC extension: a partnership with Global Runoff Data Center (GRDC) operating under the auspices of the UN World Meteorological Organisation. This extension covers 25 countries and 5,357 basins.
- CAMELS-CH extension: a CAMELS for hydrological Switzerland paper was published at the end of 2023 and along with regional data, tit includes a Caravan extension based on the global datasets.
- Several country extensions: extensions for Denmark, Israel, Spain and Iceland were produced, and more are in preparation.
Furthermore, while only basins sized between 100 km2 and 2000 km2 are included in the core Caravan, an extensions including smaller and larger catchments will be released soon.
“It is astonishing how much the availability of river flow data and associated catchment descriptors has increased over the last 10 years. Making data publicly available and usable by the community used to be the exception and is now becoming the norm. I cannot wait for the next 10 years to unfold.”
Dr Nans Addor, Principal Hydrologist at Fathom
How does the data meet Caravan’s standards?
The researchers adapted all the contributing data to be standardized, open and extensible, thus meeting all their key criteria for data.
Further, Caravan data meet five desired characteristics that enable a fully standardized and automated dataset (discussed in Addor, et al. (2019):
- They meet basic data requirements.
- They have naming conventions for hydrologically relevant variables.
- Data processing code is publicly available.
- Anthropogenic descriptors are included.
- They adhere to FAIR data standards.
At present, Caravan data lack one key feature that would further support users: uncertainty estimates. The team expects these to emerge from further research that quantifies uncertainty in global rainfall-runoff datasets and comparisons with regional datasets.
Where can I find Caravan?
Explore the current Caravan dataset (6380 watersheds) free of charge.
What makes Caravan democratic?
The research team commits to ensuring Caravan is a democratic resource – that is – any hydrologist, modeler, researcher or student can add new watersheds or data layers and process large numbers of new watersheds with minimal effort or expense. Where previously it took over a year working full-time to produce CAMELS, creating an extension using the global datasets in the Caravan platform should take people less than a week.
The main barrier to this democracy is the computational challenge of processing gridded meteorological and attributes data.
To make it as easy as possible for anyone to add or download data, all Caravan’s data-processing scripts use Google Earth Engine via Python APIs. Google Earth Engine is a free-to-use cloud service with a large catalog of geospatial data.
Users do not need to download data from Earth Engine outside of these scripts. This minimizes users’ costs, as no specific hardware is needed to carry out this task.
“In my own research work, I benefited a lot from existing large-sample hydrology (LSH) datasets. Caravan is a way of returning the favour to the community and also solving the problem of globally consistent, open, LSH datasets. Hopefully, Caravan will similarly help in advancing our field e.g. the existing CAMELS dataset were and still are.”
Dr Frederik Kratzert, lead author and Research Scientist at Google
Fathom’s scientific commitment
Fathom is committed to scientific progress, integrity and transparency.
We publish all our methodologies and research in free-to-read, academically validated papers. These papers support a global community of scientists in hydrology and related fields across academia and industry.
Explore all our open-access, peer-reviewed research on our site.
Summary
The research team envisages Caravan as the foundation of a dynamic LSH dataset that will grow over time. Anyone in the hydrology community can use and add to Caravan easily and at minimal cost.
While Caravan’s geographic spread is currently limited to some regions of the world, extensions have already substantially increased the spatial coverage, and the team hopes that Caravan will come to contain discharge data from most parts of the world as users contribute to the dataset.
Find out more about how CAMELS became Caravan in this free webinar from the British Hydrological Society.
